ReLOAD
ReLOAD: Reinforcement Learning with Optimistic Ascent-Descent for Last-Iterate Convergence in Constrained MDPs
Ted Moskovitz, Brendan O’Donoghue, Vivek Veeriah, Sebastian Flennerhag, Satinder Singh, Tom Zahavy
Check out the preprint here.
Abstract
In recent years, Reinforcement Learning (RL) has been applied to real-world problems with increasing success. Such applications often require to put constraints on the agent’s behavior. Existing algorithms for constrained RL (CRL) rely on gradient descent-ascent, but this approach comes with a caveat. While these algorithms are guaranteed to converge on average, they do not guarantee last-iterate convergence, i.e., the current policy of the agent may never converge to the optimal solution. In practice, it is often observed that the policy alternates between satisfying the constraints and maximizing the reward, rarely accomplishing both objectives simultaneously. Here, we address this problem by introducing Reinforcement Learning with Optimistic Ascent-Descent (ReLOAD), a principled CRL method with guaranteed last-iterate convergence. We demonstrate its empirical effectiveness on a wide variety of CRL problems including discrete MDPs and continuous control. In the process we establish a benchmark of challenging CRL problems.
Below, we present a few results from the Catch domain and from DeepMind Control Suite. Check out the paper for more details!
Catch
The Lagrange multiplier plot for Catch from Figure 5a is reproduced below:
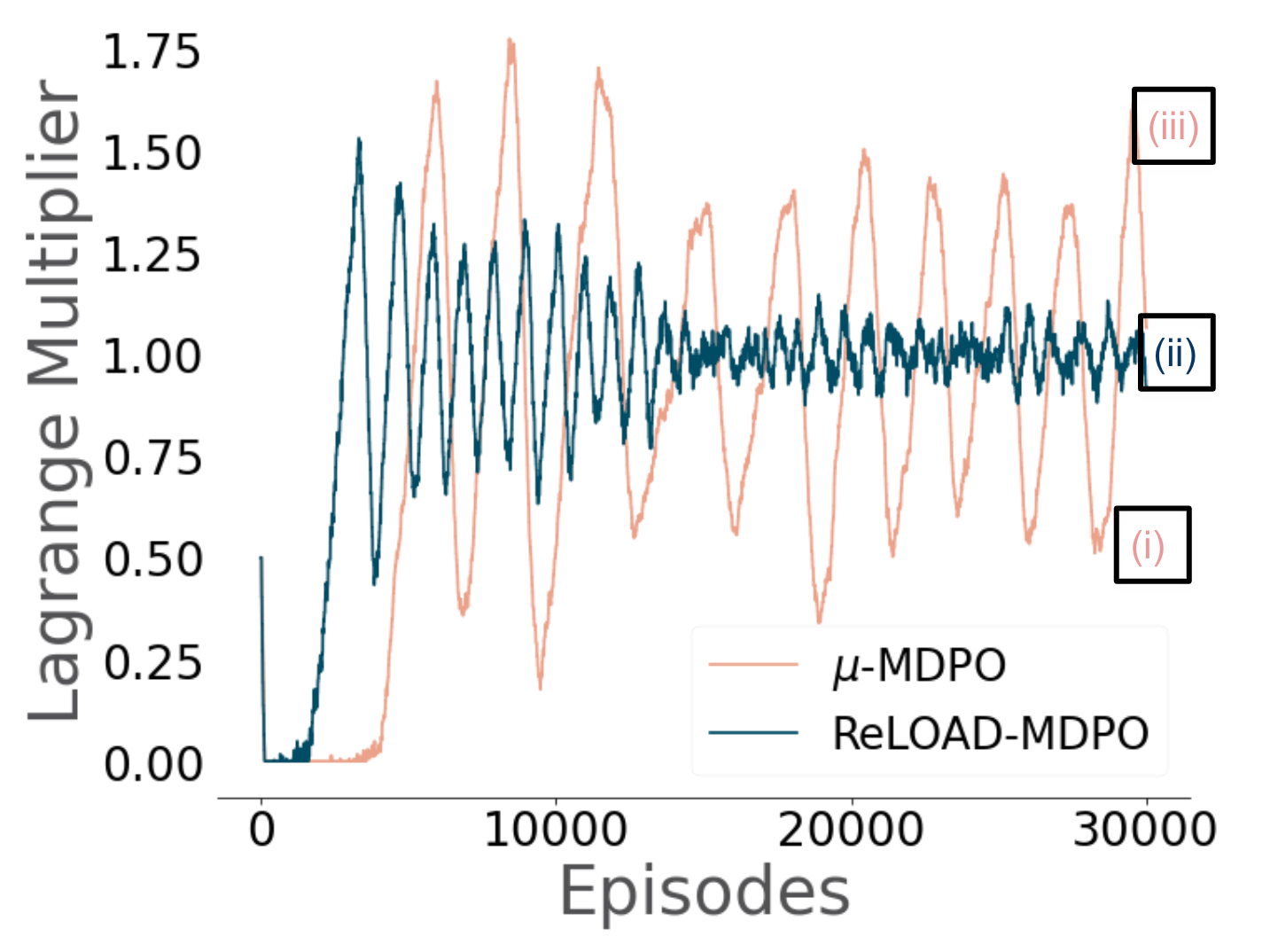
At (i), a drop in the Lagrange multiplier relative to $\mu^\star$ indicates that while the constraint to stay to the right is being satisfied, the agent is not catching the ball effectively–specifically, it is letting balls which fall on the left side of the arena drop.
At (iii), the Lagrange multiplier spikes upwards, and the opposite problem occurs: the agent ignores the constraint, lingering on the left side of the arena, but catches the ball.
ReLOAD, at (ii), manages to balance both requirements, learning a strategy in which it generally stays to the right side of the arena, but if the ball drops on the left side, it will wait until the last moment, dart out, and grab it before immediately returning to the right side.
| (i) Adhering to the constraint but letting balls drop. | (ii) ReLOAD balances both. | (iii) Violating the constraint but catching the ball. |
|---|---|---|
 |
 |
 |
Oscillating Control Suite
The themes seen above in Catch are replicated on more challenging problems in the DeepMind Control Suite.
Walker, Walk with a height constraint:
| (i) Lying down | (ii) ReLOAD walks on its knees | (iii) Walking normally |
|---|---|---|
 |
 |
 |
Reacher, Easy with a velocity constraint:
| (i) Spinning | (ii) ReLOAD touches the target but continues moving quickly | (iii) Touching the target but with little movement |
|---|---|---|
 |
 |
 |
Walker, Walk with a velocity constraint:
| (i) “The Rock” | (ii) ReLOAD walking slowly |
|---|---|
 |
 |
Quadruped with a torque constraint:
| (i) Walking normally | (ii) ReLOAD gently bouncing |
|---|---|
 |
 |
Humanoid with a height constraint:
| (i) Lying down | (ii) ReLOAD bounces up and down | (iii) Walking normally |
|---|---|---|
 |
 |
 |
Thank you for visiting!
